
前几天阿里千问发布了一堆 Qwen 3.5 系列小尺寸模型,其中 Qwen3.5-27B、Qwen3.5-35B-A3B 模型的性能按照官方评测数据已经接近去年初的 DeepSeek-R1。谁能想到现在 30B 左右参数量的模型已经可以挑战 1 年前 671B 参数量的模型。
但不要妄想小尺寸模型可以全方面赶超大尺寸模型,参数量的多少往往决定模型懂得的世界知识的多少。打个比方,大尺寸模型是武当派张三丰,百岁高龄,武功和见识最丰富,小尺寸模型算武当七侠,因为师傅牛且教得好,某套掌法、剑法使出来不比师傅张三丰差,足够行走江湖,但遇上玄冥二老这种超常规问题,还得张三丰出手。
小尺寸模型的优势在于,可本地运行,且大部分场景下性能够用。 下图中不同版本 Qwen 系列 30B 左右的模型的 MMLU-Pro 得分,能看出小尺寸模型的性能提升非常迅速,基本直线向上。
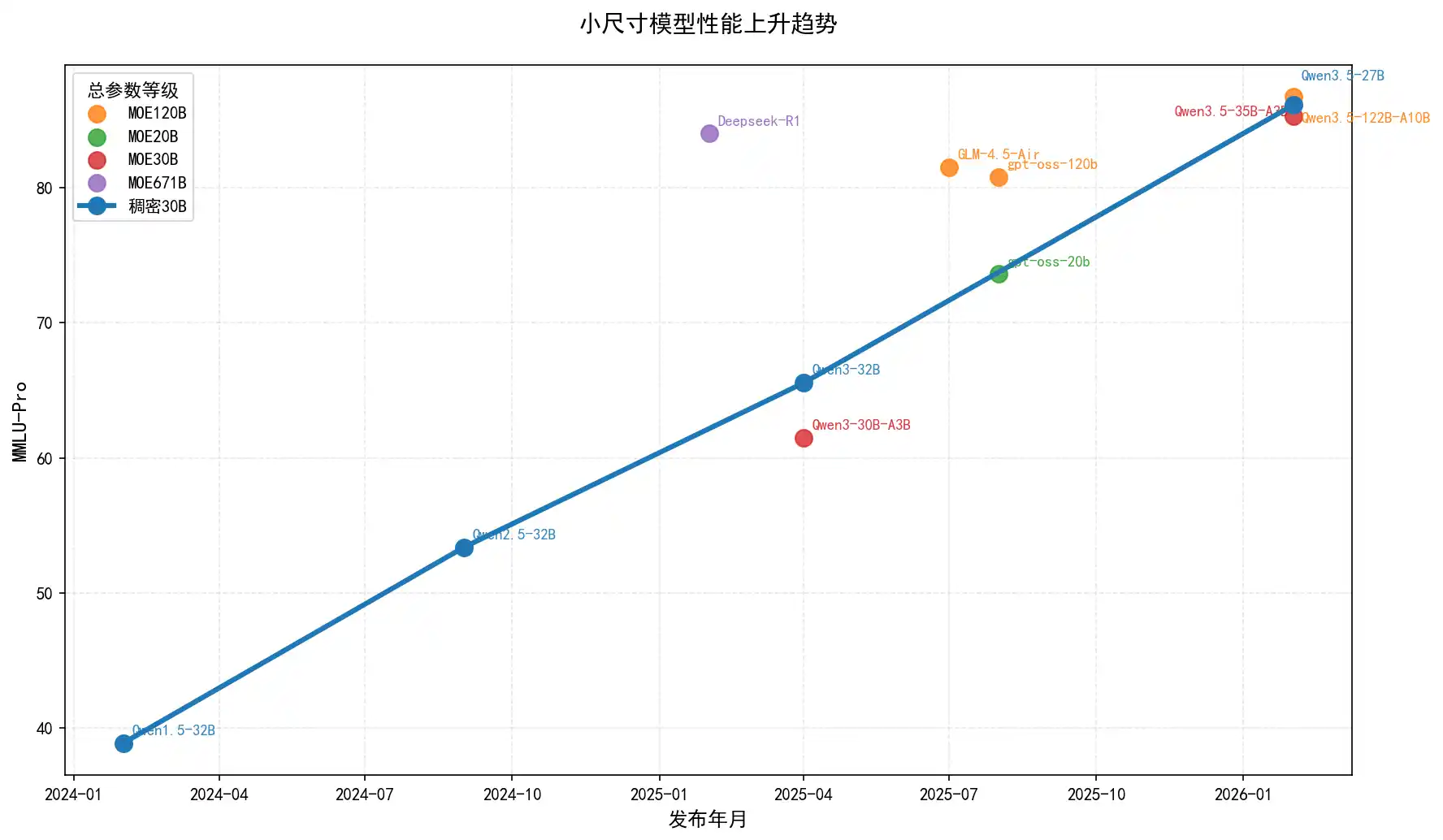
是否能推论出:DeepSeek-R1 够用的场景,现在 Qwen3.5-27B、Qwen3.5-35B-A3B 也基本够用?
进一步推论:如果小尺寸模型性能继续提升至某个程度,等到可以流畅运行小尺寸模型的硬件设备价格降低到某个程度,家用本地 AI 会得到广泛普及, 『家里有个 24 小时干活的人工智能』成为普遍情况,就如当年电脑和智能手机走进千家万户,极大改变工作、生活和社会,那时候或许才是 AI 时代真正的面貌。
现阶段运行本地模型的硬件,对于普通用户仍然较贵。今年流行的 OpenClaw,已经有点 AI 走进千家万户的苗头了。OpenClaw 是个吃 token 大户,使用模型厂商 API 的费用很可观。下表对比本地运行模型与使用在线模型 API 的成本。
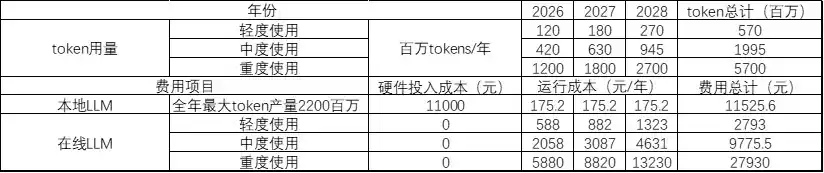
表中计算的前提条件:
- 轻度、中度、重度使用 OpenClaw 的 token 用量参考文章:《OpenClaw 为什么这么费 Token?6 个原因分析与省钱攻略》,2026 年参考文中数量,后两年每年按照前一年 1.5 倍。
- 本地运行大模型的硬件按照 MAC Mini M4 Pro 48GB+512GB,运行成本按照 40W 功率全年运行的电费(电价 0.5 元/kWh)。
- 本地运行大模型按照 Qwen3.5-35B-A3B,阿里百炼的 API 价格大约为 4.9 元/百万 token,MAC Mini M4 Pro 生成速度约为 70 tokens/s,全年不停大概能生成 2200 百万个 token。
- 现在 AI 发展太快,成本计算按照未来 3 年粗算总费用。
仅通过表中粗算 3 年总成本费用,对于中轻度用户,直接使用模型厂商在线 API 服务更划算,重度用户自己电脑本地运行大模型服务可能更省钱。
但需注意,重度用户除了处理邮件、总结文章、安排进程这类普通办公场景,可能还需要 AI 具备编写代码、处理超大文本等高等技能。而 30B 尺寸模型在这类技能上的水平是不如大尺寸模型的。如果本地运行 100B 或 200B 模型,例如 MiniMax M2.5,硬件成本要飞起。这还没考虑高并发的需求。Mini M4 Pro 生成速度约为 70 tokens/s,全年不停大概能生成 2200 百万个 token,也不够重度用量的。
所以『家用本地 AI 会得到广泛普及』的来临,要期待中小参数量模型的性能继续提升,跑本地 AI 硬件设备的价格继续降低。
但按照目前内存、SSD 价格起飞态势,一两年内硬件设备怕是只会涨价😂。